Could your website be too ‘thin’ to rank well? Are you even aware of the ways it could be lacking in quality? Thin, duplicate, and overlapping content are important to minimise in relation to your website’s SEO health, because they all impact not only the user experience but also how search engines think about your website’s quality. So, how do you identify thin content, and how can it improve your SEO?
Consistent, quality content will lead to a higher topical authority level, which can increase your rankings. Thin content can be identified by:
- Reading through every page carefully
- Looking for content that appears on multiple pages in the same format
- Looking for empty spaces where more information could be included
- Considering whether a page features original content, thoughts, or analyses
- Looking for low-effort arguments and talking points
Keep reading to learn how thin content and topical authority affect your search rankings, and how you can fix thin content on your website in detail.
Jump To:
- What is Thin Content?
- What is Topical Authority?
- Modern Causes of Duplicate Content
- Practical Fixes for Thin Content

What is Thin Content?
Thin content is content that lacks either quantity, quality, or both. This means that the content:
- Fails to resolve the reader’s problem
- Fails to meet their intent
- Fails to encourage them to convert
There is no point in having thin content. At best, readers leave with the intention of seeking the next best alternative. At worst, it results in a hit to your overall topical authority, a drop in search rankings, and a decrease in website traffic.
Types of Thin Content
If you want your website to grow organically, you need to ensure there is no thin content (editorial or technical) on any of its pages. Types of thin content include:
- Duplicate content
- Content scraped from another website
- AI-generated content
- Shallow blogs lacking depth or unique insights
- Low-value product pages
- Thin affiliate pages
- Doorway pages
Duplicate Content
A good SEO practice is to ensure that every page on your website is unique. This sets you up well for internal backlinking (yes, just like that one!), and it improves the user experience by reducing uncertainty about whether they’re seeing the correct page.
‘Duplicate content’ refers to content that is identical between one or more webpages on a domain, subdomain, or across the internet at large.
Duplicate content reduces the value of individual pages by diluting the pool of information available, making it harder for users and search engines to find original, valuable content. This, subsequently, could result in a page not ranking.
Scraped or Copied Content
Scraped and copied content is closer to blatant plagiarism. Sometimes small chunks of text are copied; other times, entire pages (or even multiple pages) are scraped. This applies to all kinds of stolen content, including unattributed quotes. Plagiarism is not only bad on a legal and moral level, but it’s also bad for both SEO and user experiences.
AI-Generated Content
Content that was generated using software like ChatGPT or Copilot can be considered thin when it fails to offer original insights or firsthand experiences. LLMs inherently draw on other content to generate their own, meaning they struggle to provide meaningfully original insights, new information, or firsthand experiences.
Shallow Blogs Lacking Depth or Unique Insights
These are blogs that have nothing original to say, or do say something unique, but fail to explore further.
Consider whether the blogs you’ve got currently are parroting the same things as everyone else, and try to identify where you can add your own perspective to the narrative, or your own texture to the writing.
Low-Value Product Pages
A product page might be seen as low-value if it fails to communicate key information about the products, is broken on a technical level, or just looks uninspiring. Make sure that all the information a customer would want to know is available at a glance:
- What does the product look like?
- How much does it cost?
- Are there variations, like alternate colours or materials?
- Is it on sale?
- How well is the product reviewed?
Product pages with only a handful of products could also be classified as low-value. This often happens if you’ve narrowed down your categories too much, or if you just don’t have enough products to make a page feel full.
Tackle this by restructuring your product pages without being dishonest; it is okay to sometimes have only a few products on a page, just make sure it’s not the case on every product page.
Thin Affiliate Pages
An affiliate page is a page whose value comes from the fact that it is linked to something else, somewhere else. These are usually about products; you’ll have heard an influencer talk about the “affiliate links down below”.
Thin affiliation involves copying product descriptions and reviews directly from the original merchant without any additional value. Google might see your syndication of the original content as a violation of their quality guidelines and subsequently remove your page from their index. Improve your affiliate pages by adding:
- Additional information about the price
- Original product reviews
- Results from your own testing
- Improved product navigation or categorisation
- Product comparisons
Doorway Pages
Doorway pages cater to specific, very similar queries to those of a website’s actual domain in order to dominate a chosen keyword on the results page. This is a form of spam.
They create intermediate pages that don’t provide as much value as the final destination, funnelling users through pages to force unnatural traffic.
Google hates doorway pages tailored to exploit search engines because they can lead to, in the worst cases, entire results pages featuring unique links that all lead to the same single website. As a user, this is an incredibly frustrating experience.
Google Versus Thin Content
From 2022–24, Google rolled out the ‘Helpful Content Update’, which refreshed how topical authority was judged. The update elevated content that was helpful, high-quality, and displayed firsthand experience, before it became part of Google’s core ranking systems in 2024. The update primarily intends to prevent large-scale, low-quality, automated and AI-generated content from ranking above webpages with genuine, people-first value, based on the content’s EEAT factors and Google’s human search quality evaluator guidelines.

What is ‘Topical Authority’ and How is it Threatened by Thin Content?
Topical authority refers to your website’s overall level of expertise and credibility on a particular topic.
It fundamentally relies on the principles of E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) to determine whether you have anything original or of quality to say. You can check a domain’s topical authority by using SEO tools like SEMrush.
Topical authority and EEAT factors become more important if your website deals with sensitive issues. These kinds of websites are known as YMYL, which you can learn more about in our blog: What is YMYL & Why it Matters for SEO
High Topical Authority is Essential for SEO
Your website needs a high level of topical authority on its chosen subjects because it demonstrates that:
- Search engines trust your website
- Thus, users should trust your website
- Thus, your rankings and conversions should improve
The Threat of Thin Content
If the content on your website is consistently thin, Google will think that you are not an authority on the subject and will reduce your topical authority ‘score’. You will find, for example, that if you have AI-generated content on your website, search engines and insightful users will trust that content less because it doesn’t display first-hand experience.
Topical Authority Example: Wildcat Digital
For example, Wildcat Digital has a ‘High’ level of topical authority for the keyword ‘SEO agency Sheffield’, a ‘Relevant’ level of topical authority for the keyword ‘Marketing’, and a ‘Low’ level of topical authority for the keyword ‘Spaceships’.
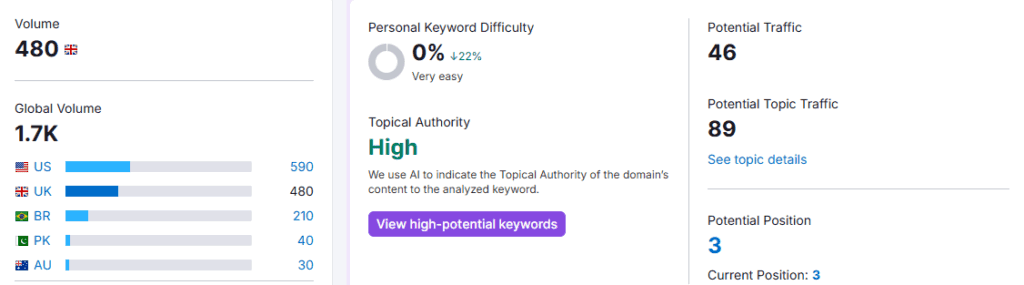
This means that when someone searches “SEO agency Sheffield” into an LLM or search engine, Wildcat Digital’s website will be prioritised as a trustworthy source of information for that topic, resulting in a citation or higher results page rank. We wouldn’t get cited for questions about Area 51, though.

Bob thinks he’s cracked the case, but little does he know… BOB was the duplicate content all along!
Modern Causes of Duplicate Content
Duplicate content is one of the more important types of thin content because, while duplication doesn’t specifically get punished by Google, it does have knock-on consequences for the user experience.
Duplication happens for a lot of reasons, some accidental, some intentional, some exploitative. The three main reasons for duplicate content, however, are:
- AI-generated repetition
- Syndicated, quoted, and copied content
- Technical duplications & URL variations
AI-Generated Repetition
Generative AI and LLMs are trained on pre-existing content, meaning that anything they output after will be a regurgitation of something which already exists.
This can also involve repetitive phrasing. Think about how much of what ChatGPT says sounds so similar, so clean, so friendly. Users can subconsciously identify such weak, repetitive writing and, when they do, they bounce away.
Using AI-generated content as a placeholder to fill space on your website is pointless. At best, using AI-generated content will result in users bouncing from your page. At worst, your page’s ranking and topical authority score will be treated as if you were using scraped or plagiarised content.
Syndicated, Quoted, and Copied Content
Syndicated content is content taken from another website directly without making changes or adding value. Inherently, this creates duplicate content on the internet.
In some cases, syndicating content from another website is acceptable, particularly if you correctly attribute credit by linking to the original and using a canonical URL or meta robots noindex tag. Not every website owner will be happy with this, however, and you should always ask for permission first anyway.
Technical Duplications & URL Variations
There are ways that you can accidentally (and intentionally) end up with duplicated technical elements, commonly identified by their variations in page URLs.
Printer-Friendly Pages
Pages with a printer-friendly version on a separate URL (for example, eg.com/print/blog-content vs eg.com/blog-content) are considered duplicate content if there is no canonical URL implementation for the main version.
URL Variations
URL variations such as parameters, session IDs, and tracking and analytics codes have the potential to cause duplicate content issues because they can construct URLs that are almost identical.
Often, this is caused by human error and misunderstanding what a URL actually is, both by yourself (or whoever works on your site), or from the developer who doesn’t prioritise SEO – they quite literally speak a different language!
WWW. (vs Non-WWW.) & HTTPS (vs HTTP) Pages
If a website has separate versions of webpages (www.page.com vs page.com), with the same content, these are effectively duplicate content.
The same applies to sites that use both http:// and https://. For reference, http:// is the same as https:// with the only difference being that https:// includes encryption and verification, making the page more secure and ideal for eCommerce sites or sites that capture personal information.

Practical Fixes for Thin Content
Whilst you can reverse the effects of thin content penalties, it’s best to avoid them altogether or fix them as soon as possible. Follow our decision tree to help you decide how to deal with thin content, and read about each piece of advice in more depth below.
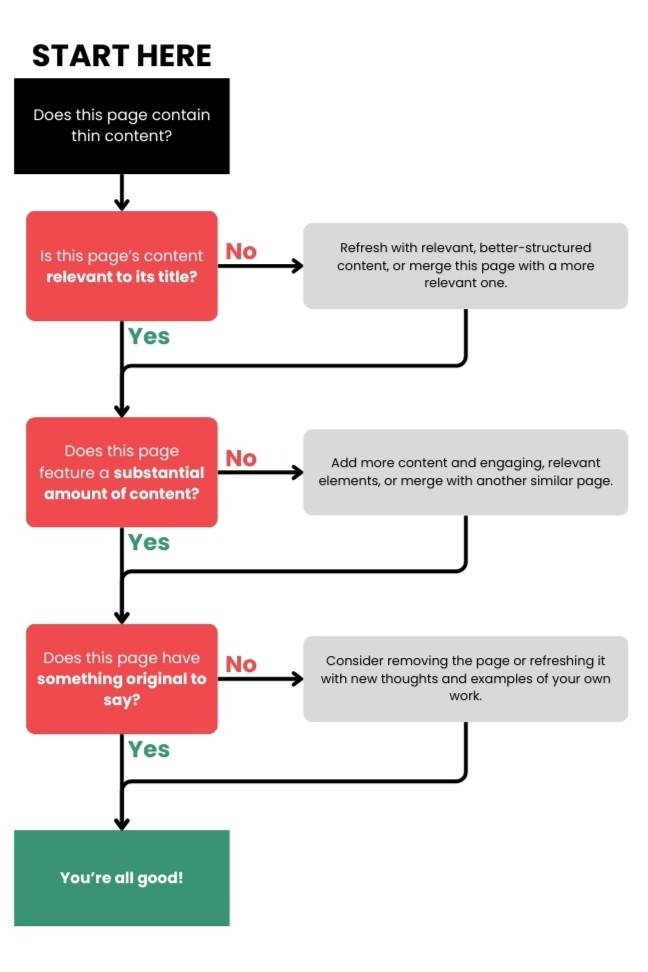
Refresh, Merge, or Remove Low-Quality Content
Low-quality content can be made more SEO-friendly by giving it a refresh, merging it with higher-quality content, or removing it entirely. First, though, you need to find the thin content.
To find content that might be considered thin or duplicate, conduct a mini content audit of your own website. Read through your blogs, landing pages, product listings, and everything in between and assess whether each page has all of the following features:
- Content that is relevant to the page’s title and user intention
- A substantial amount of content
- Something original to say
Relevant Content and Matched User Intention
Sometimes you start writing, fall down a rabbit hole, and suddenly your latest blog is 4000 words long and includes incoherent details about the Treaty of Versailles. We content writers are empathetic; search engines are not.
Deal with irrelevant content by consistently linking back to your title as you write. Additionally, put the most important information at the top of the page. This is done for two reasons:
- Readers want quick answers and won’t read a whole page to find them
- Search engines will find confirmation of your relevance and authority quicker
Following this advice will naturally match the user’s intent to your page better. If a user clicks on your blog titled ‘How To Teach Your Cat to read’, they’ll be very disappointed to discover that it’s actually a blog about how to potty train dogs.

Page titles, H1s, and title tags all contain information for search engines about what a page is about. If the body of that page is then not aligned with the title, Google will think you’re not an authority on the subject, and your page won’t rank.
Substantial Amount of Content
A good blog length is 1000 words. Some are longer, and some are shorter, depending on necessity, but 1000 words is a good general-use target. How long are your blogs?
There are fewer rules for other types of pages, but the core point is that if a page doesn’t feature enough content, search engines will think it has no value to add to the subject and won’t prioritise it in the rankings.
Simple solution: add more content- wait! The extra content does actually need to be of value, don’t just AI-generate more words.
When adding new substantive content to your pages, try to fulfil some EEAT criteria, especially if your website is YMYL. Consider how you can demonstrate your expertise, experience, authority, and trustworthiness on this topic. This could include:
- First-hand accounts
- Original images
- User or customer reviews
- Proof of certifications and qualifications
Read more about EEAT factors and how to optimise for them in our blog: What is EEAT in SEO & Why is EEAT Important?
Originality
Finally, your content must include something original. Whether that’s in-depth breakdowns of your services, well-researched think pieces, or quotes no one else has got, your content will fail if it parrots what everyone else is saying.
The best way you can spawn some originality is by considering your true thoughts on the alternatives. If you’re creating a service or product page, research what your competitors are doing and look for gaps. If you’re writing a blog, try to empathise with another perspective and argue against yourself.
Technical Fixes
Canonicalise the Primary Version of a Page
Canonicalisation involves specifying which version of a page is the primary version that you want to appear in search results. There are two key methods for enforcing canonicalisation.
301 Redirects
301 redirects are often the best way to fix URL duplication because they literally redirect the duplicated page to the one that you want to appear in search results. This stops the duplicate pages from competing with each other and also creates a stronger relevancy and popularity signal that will positively impact the master page.
Rel=”Canonical”
Rel=”Canonical” tags tell search engines to actually treat the tagged page as duplicate content and to attribute any value from links, content, metrics, and “ranking power” to the specified URL.
‘No Index’ Thin and Duplicate Pages
You can hide pages with necessary thin or duplicate content from search engine results pages (SERPs) by adding a ‘no index’ tag. This tells search engine crawlers to exclude the tagged page from indexing, ensuring that the page can’t appear on SERPs and, therefore, won’t compete with other pages.

Jon Herdman
SEO Executive