
If you’re new to SEO, some of the more technical aspects of it can seem a bit confusing and overwhelming, especially if you’re not from a technical or web development background to begin with. Robots.txt is one such aspect of Technical SEO that causes more than a few head-scratches, so we got one of our Senior SEO Account Managers to take you through it. Let’s start with the basics; what exactly is robots.txt?
Robots.txt is a text file on your website that instructs web robots and crawlers on which pages they should or should not access. When it comes to search engine agents, the robots.txt file allows us to stop Googlebot, Bingbot, and other crawlers from accessing certain areas of your site, and better manage the crawl budget.
The robots.txt file is part of a number of tools that website owners and developers can use to implement the Robots Exclusion Protocol, alongside X-robots-tags, robots meta tags, and rel attributes.
Read on to find out more about how and why we use robots.txt files.
How does robots.txt work?
Robots.txt is a simple text file, without any HTML markup. It is hosted on the web server, located at the root of your domain, and it is publicly accessible. If a website has a robots.txt file, you will be able to find it by typing in the URL followed by /robots.txt
Robots.txt is the first file that search crawlers read after reaching a domain. This file provides bots with information on how to crawl the website and what pages, resources, or folders they should not crawl. If the bots do not find a robots.txt or if the file does not contain any disallow directives, it is implied that they can crawl all the links found on the domain.
The file contains lines of text. Each line specifies a rule for one or more crawlers, allowing or disallowing their access to specific file paths on the domain.

Wildcat’s robots.txt file indicates that all crawlers can access all URLs on the site. It also points to the specific location of the XML sitemap.
What is robots.txt used for?
The main goal of the robots.txt file is to manage good* bot traffic and activity, so the crawl budget is used effectively and servers do not become overloaded. There most common uses of robots.txt include allowing and disallowing specific agents, directories, or files and specifying the location of your sitemap.
*more detail on this point under Limitations
How to create a robots.txt file
Many website builders will create a robots.txt file by default. Here is how you can create your robots.txt file if your website does not already have one, and how you can optimise your existing file.
- To create your file open a text editor like Notepad or Sublime Text.
- Use valid syntax to specify your agent and rules.
- Save the file with the name robots.txt, making sure that the file is saved in plain text format (not rich text or any other format).
- Test your file using an online validator like the Merkel robots.txt testing tool.
- Upload the file to the root directory of your website using FTP or your hosting control panel.
- Once your file is uploaded, you can also test for errors and warnings with Google’s Search Console robots.txt tester or paid crawling tools like Sitebulb and Screaming Frog
- You should also check your Coverage report in Google Search Console for any instances of URLs blocked by robots.txt.
Syntax
The robot.txt file is structured as a series of lines, where each line contains a single field specifying a user-agent, allow directive, disallow directive, or sitemap location. The order of these fields matters to the proper understanding of the file. Below, we will outline the most important rules to follow when writing your robots.txt file.
User-agent
Defines the web crawler or user agent that the rule applies to. It can be a specific agent or a wildcard (*) for all agents.
Disallow
The disallow command is the most commonly used directive in robots.txt. It tells crawlers to omit certain areas of the site. It can be used to:
- Block access to a whole website
User-agent: *
Disallow: /
- Block access to a single file or page path
User-agent: *
Disallow: /wp-login.php
- Block access to a whole directory
User-agent: *
Disallow: /wp-admin/
- Block access to private pages
User-agent: *
Disallow: /my-account/secret-info
- Block the crawling of search query string parameters and other irrelevant dynamic and static URLs
User-agent: *
Disallow: /shop/?query=*
Allow
The allow command does just that – it allows bots to access certain pages or directories. Because bots will always follow the most specific command on the file. The allow directive can be used to, for example, allow access to a specific page within a disallowed directory. Or, to allow one crawler access while disallowing all others.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemaps
Adding a link to the XML sitemap in your robots.txt file helps readers find all your pages and understand what you deem to be the most important links on your site.
User-agent: *
Disallow:
Sitemap: https://wildcatdigital.co.uk/sitemap_index.xml
Crawl delay*
The crawl delay directive can be used to tell the user agent to wait for a specified number of milliseconds between crawl requests. This helps avoid overtaxing the server.
*While Bing and Yandex still recognise this directive, Google no longer does. However, the crawl frequency for Google bot can be set through Google Search Console.
Field order and grouping in robots.txt
Understanding the logic robots use to read your file can help you write effective rules.
- You can group directives. Every directive should be on a separate line. Every directive between one user-agent field and the next user-agent field applies to the first user-agent.
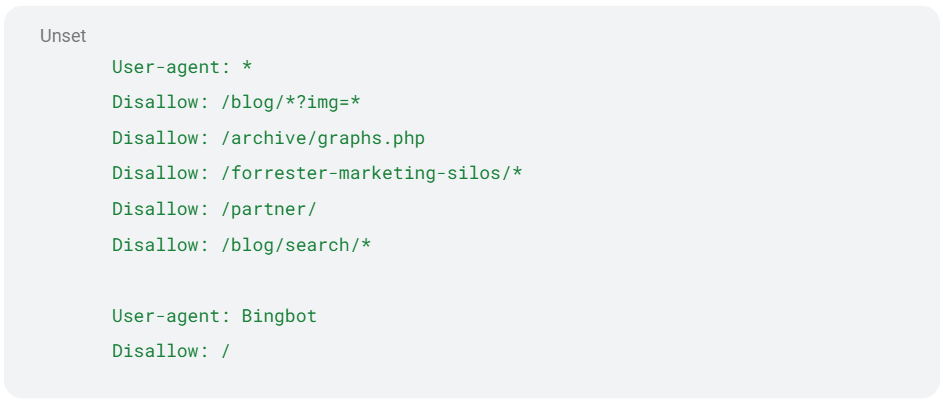
Snippet from Semrush’s robots.txt file. All of the directives below the user agent field apply to that user agent. In this case, all user agents.
- You can define rules that apply to multiple users by stacking user-agent lines for each relevant crawler before the rule.

In this configuration, all other bots will follow the first group of rules, where no disallows are in place. Both Yahoo and Yandex will follow the second group and will not crawl any of the pages in the domain.
- Crawlers read groups from top to bottom.
- Only one group of rules can apply to a particular crawler. When several groups are applicable, the crawler will follow the most specific set of rules for that user-agent, based on the length of the rule path.

Because both rules apply to Googlebot (the disallow rule applies to all bots), Googlebot will follow the second, more specific directive.
- When two specific and conflicting rules apply to the same user agent, Google and major search engines will opt for the least restrictive rule.

This example, from Google’s documentation, specifies that in this case, the Google bots will follow the allow directive.
- The (*) Wildcard is used to match any sequence of characters. It can be used for user-agent and all directives, except sitemap. This wildcard is used to simplify directives, as the pattern matching allows us to apply rules to any URL matching a specific pattern, without having to list them individually.

The example above disallows crawling for all dynamic shop search URLs.
- The ($) Wildcard can be used to match the end of URLs. This is useful when trying to block access to a specific type of file, for example.

Disallows all URLs ending in .php

Disallows the root URL without disallowing lower-level URLs like /root/file.
- The (#) symbol can be used to mark comments, which will be ignored by crawlers.
Robots.txt Limitations
For all its useful implementations, the robots.txt file has certain limitations that are important to know about before making any changes.
Robots.txt does not enforce directives
It is important to note that the commands contained in the robots.txt file are directives, not rules. This means that malicious bots and crawlers can choose to ignore these directives. While you can rely on Google, Bing and most good bots to follow these directives, you must employ alternative methods to truly protect sensitive content on your website, like password-protecting files.
Disallowed pages can be indexed
The disallow directives on the robots.txt file stop search engine crawlers from reading the content of the disallowed pages. However, when these pages are linked to from other crawlable pages, they may still be indexed and appear in search results.
No index directives in the robots.txt file are not supported by Google, and the robots.txt file directives should not be used to manipulate search results.
To reliably prevent certain pages from appearing in search results, we can use noindex robot directives on the necessary pages.

Need Help With Your robots.txt File?
Our team of technical SEO specialists at Wildcat Digital have a wealth of experience setting up websites for success. Checking that your robots.txt is set up correctly and following best practices is a key step in our technical audits and campaign planning. If you need help with your robots.txt or have any concerns about the indexing and crawling of your website, get in touch today.


























